
The launch of DeepSeek’s cutting-edge AI model has caused quite a stir in the tech industry, especially in Silicon Valley. For years, the prevailing narrative in AI development was that building a robust foundational model required significant financial investments—often in the hundreds of millions of dollars. This idea was considered almost unquestionable, as companies like OpenAI, Google, and others invested vast amounts in developing state-of-the-art large language models (LLMs) and other AI systems. However, the introduction of DeepSeek has shaken this traditional approach to its core. Despite spending just $6 million on its development, the DeepSeek AI model has been able to achieve remarkable results, outcompeting traditional human-led startups, with AI agents taking center stage in the model's operations. But what exactly is DeepSeek, and why is it drawing so much attention?
What Makes DeepSeek Different?
At its core, DeepSeek is an AI model designed to minimize the reliance on expensive hardware, particularly high-performance GPUs, which are crucial for the training of large-scale models. This breakthrough in reducing hardware dependence is partly why Nvidia’s stock experienced a downturn recently, with DeepSeek’s efficiency being a direct challenge to the traditional reliance on GPUs. However, this is not the only reason why DeepSeek is generating a buzz in the AI and cryptocurrency sectors. Its innovations in AI architecture open the door for smaller teams, even with limited resources, to build high-performing AI systems that could be deployed in a wide range of applications. Here's a deep dive into the technical aspects of the DeepSeek AI model and how it represents a major advancement over traditional approaches.
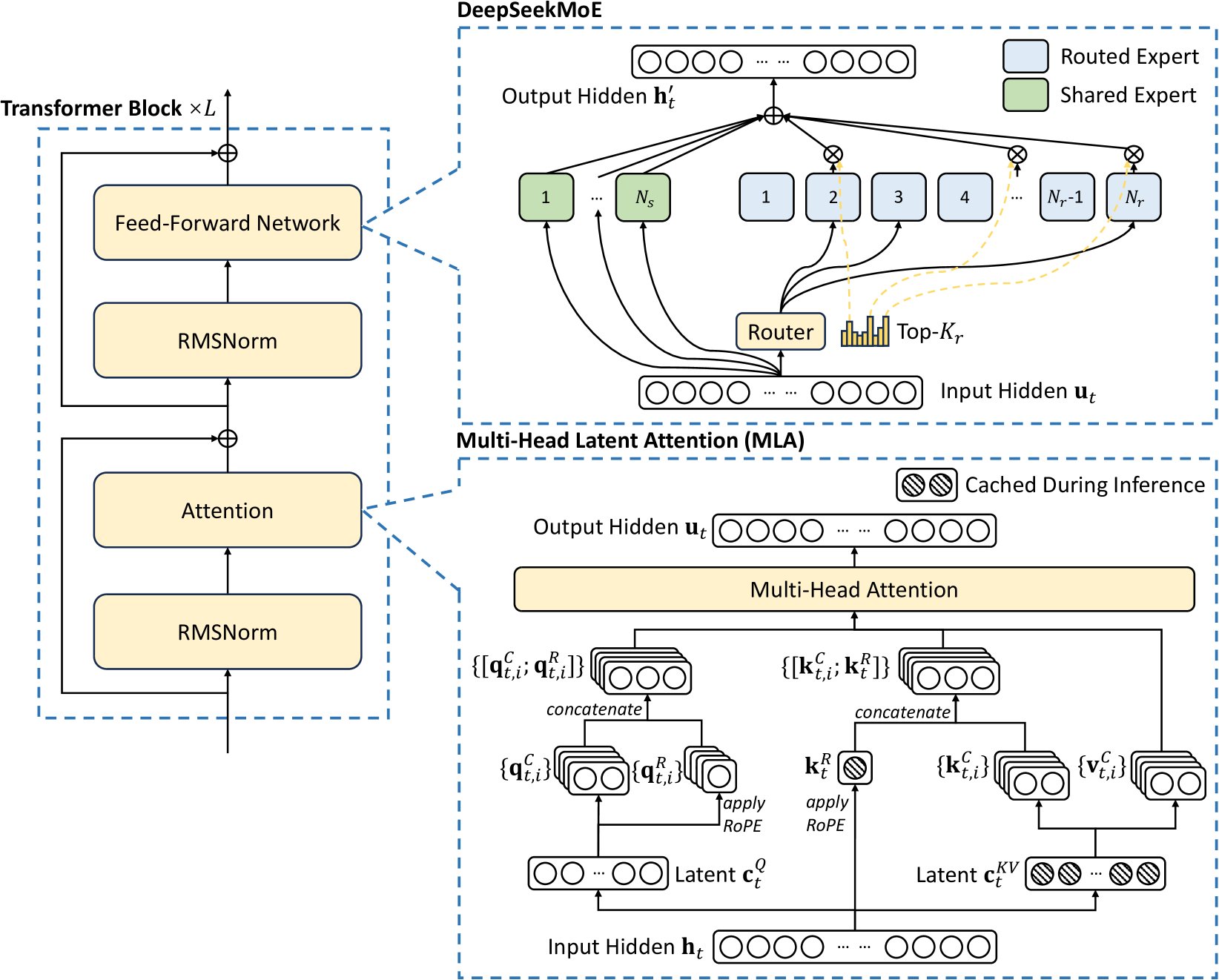
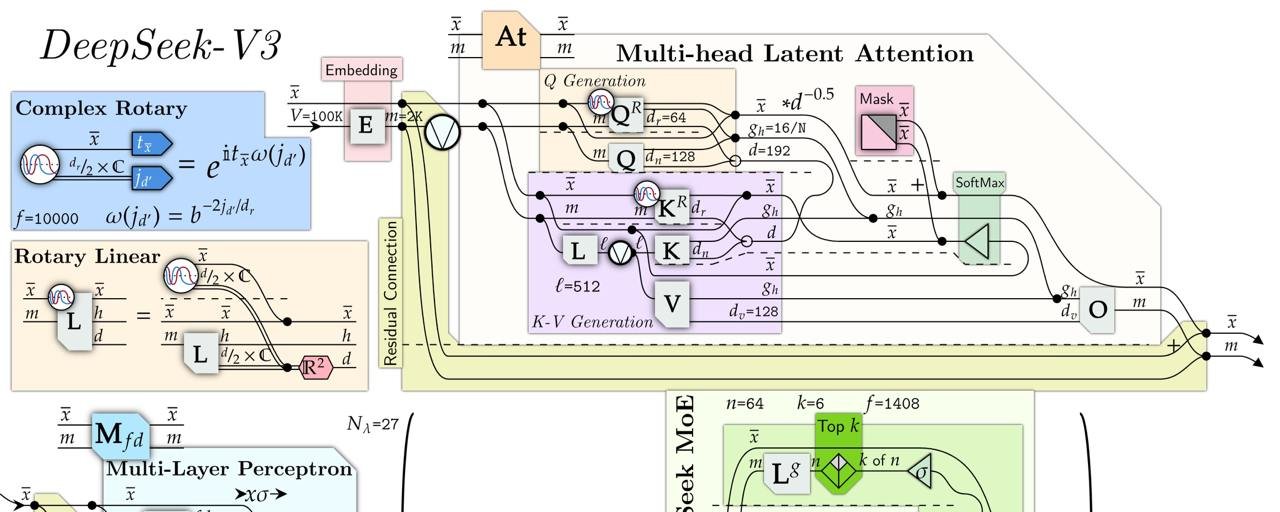
1. Multi-Head Latent Attention (MLA): Compressing Data Without Losing Information
One of the most innovative features of DeepSeek is its Multi-Head Latent Attention (MLA) mechanism, which stands as a major improvement over the standard Transformer model architecture. In traditional Transformers, each token's Key and Value vectors (KV) share the same dimension as the Query vectors. However, DeepSeek reduces the size of these KV vectors by utilizing a low-rank compression technique, resulting in a compressed latent space for the Keys and Values.
Compression through MLA: By projecting the hidden representation of the data into a low-dimensional space, the system reduces memory usage significantly while preserving important information. This is analogous to compressing files into a zip format—while the file size is reduced, the quality of the content remains largely the same.
Selective Positional Embeddings: The model applies decoupled positional embeddings selectively to only a portion of the Key/Value vectors. This selective application further reduces the memory footprint while maintaining crucial positional information, which is key to understanding the relationships between different tokens in a sequence.
By implementing these optimizations, DeepSeek dramatically slashes the size of its Key/Value caches during inference, lowering memory demands and thus enhancing efficiency. Even with the down-projection, the accuracy of the model is largely preserved, making it a highly efficient architecture for a variety of use cases.
2. Mixture of Experts (MoE): Efficient Scaling of Computational Power
DeepSeek’s use of the Mixture of Experts (MoE) architecture is another breakthrough. Traditional models, such as those using dense layers, treat every token with equal computational cost. In contrast, DeepSeek uses expert blocks—groups of specialized, smaller models that share computational resources—thus allowing the model to scale without incurring the cost of using all available parameters for every token.
Expert Routing: Instead of using the entire feed-forward capacity for each token, DeepSeek routes tokens to only a small subset of experts. This ensures that each token is processed by a specific “specialty expert,” akin to a doctor consulting specialists only when necessary. This not only reduces computational costs but also makes the model more efficient.
Dynamic Load Balancing: One challenge with MoE is the potential for load imbalance, where some experts may get overwhelmed with tokens while others remain underutilized. DeepSeek employs an "auxiliary-loss-free" method to address this. Unlike previous MoE architectures, which use a loss function to penalize overloaded experts, DeepSeek dynamically adjusts small bias terms to ensure tokens are evenly distributed across experts without introducing performance-degrading penalties.
This dynamic load-balancing method helps DeepSeek maintain high efficiency, preventing the inefficiencies typically associated with other MoE models. By ensuring that only a small subset of experts are activated for each token, DeepSeek achieves significant improvements in computational efficiency, with a fraction of the resources typically required.
3. Multi-Token Prediction (MTP): A Powerful Training Technique
DeepSeek introduces Multi-Token Prediction (MTP), a technique designed to enhance the model’s ability to understand and predict sequences. Unlike typical models, which predict only the next token in the sequence, DeepSeek trains each token’s hidden state to predict multiple subsequent tokens in parallel.
Parallel Predictions: This is done by appending a chain of additional Transformer blocks and output heads to each token representation. These modules sequentially predict one or more future tokens, and during training, these predictions are used to add an auxiliary loss term that strengthens the model's understanding of the entire sequence.
Speculative Decoding: During inference, the additional predictions can be discarded or used for "speculative decoding," which allows for faster text generation by predicting multiple tokens at once. This approach not only densifies the training signal but also aids in improving the model's ability to understand longer-term dependencies within a sequence.
By training the model to predict multiple tokens simultaneously, DeepSeek encourages stronger learning of global sequence structures, which improves its ability to generate coherent, contextually relevant outputs over extended texts.
4. Efficient Infrastructure and Parallelism Strategies
DeepSeek is optimized for efficiency through the use of advanced parallelism strategies. For example, it uses DualPipe for pipeline parallelism, which helps reduce communication overhead during training, allowing for faster and more efficient training processes.
Additionally, DeepSeek employs FP8-based mixed-precision training, which reduces computational costs by optimizing quantization and accumulation processes. This enables the model to train on fewer resources while still maintaining high levels of performance.
5. Comparison with Traditional Large Language Models (LLMs)
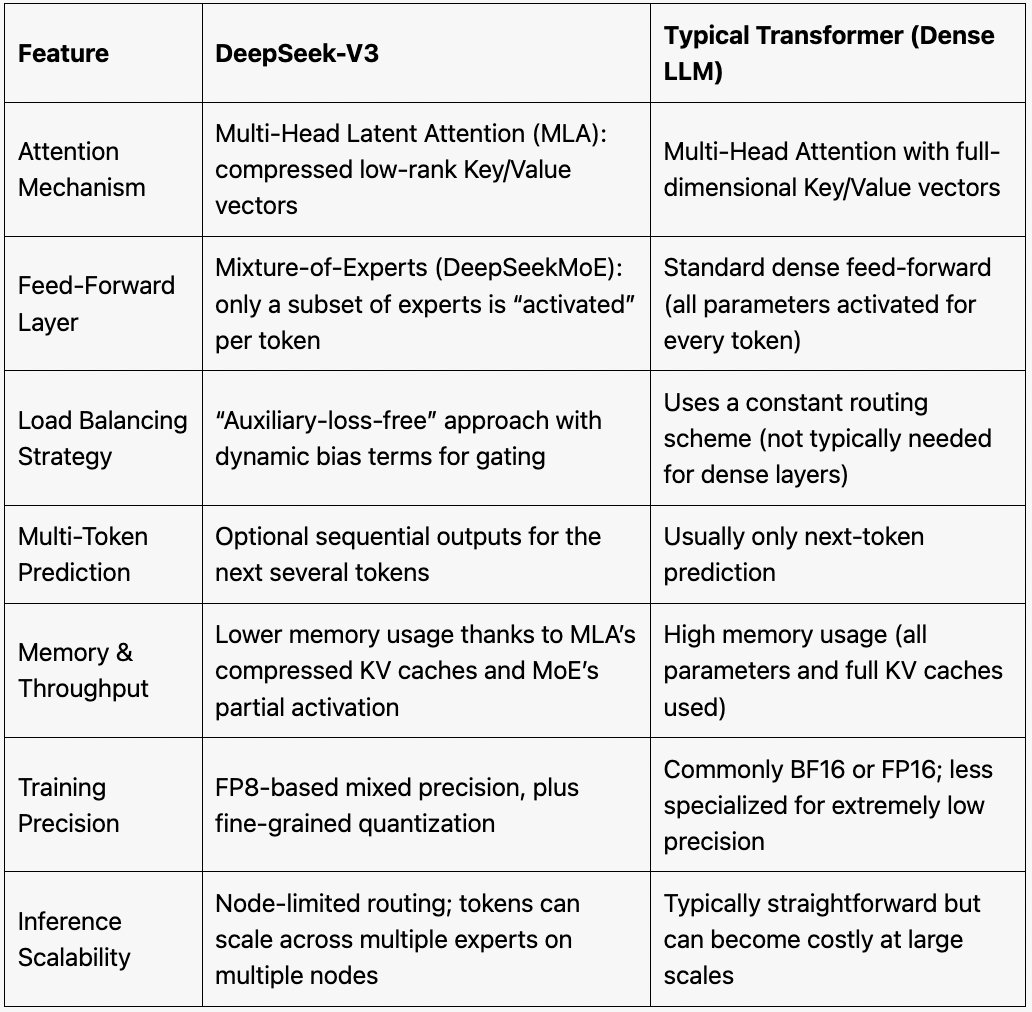
To understand the significance of DeepSeek’s innovations, it’s helpful to compare it with traditional large language models:
FeatureTraditional LLMsDeepSeek-V3Memory EfficiencyHigh memory usage across all tokensReduced memory usage via MLA compressionComputational EfficiencyEvery token processes through all parametersOnly a small subset of experts are activated per tokenTraining StabilityProne to instability due to load imbalancesRobust load balancing with dynamic bias adjustmentsPrediction SpeedStandard next-token predictionMulti-token prediction for faster generationScalabilityHigh computational cost for scalingEfficient scaling with fewer GPUs and fewer layers
DeepSeek’s innovations make it more scalable and computationally efficient than traditional LLMs, without sacrificing performance or accuracy. By reducing memory and computational costs while enhancing prediction capabilities, DeepSeek offers a powerful alternative to traditional models, making it ideal for real-world applications where computational resources may be limited.
Conclusion: Democratizing AI Development
DeepSeek is a game-changer in the world of AI development. Its use of MLA compression, MoE architecture, multi-token prediction, and efficient parallelism strategies allows it to achieve performance levels comparable to larger, more resource-hungry models while using far fewer resources. This efficiency opens up new possibilities for smaller teams and startups, enabling them to build high-performance AI models without the need for vast amounts of computational power.
By making these powerful AI models accessible to a wider range of developers, DeepSeek accelerates the development of AI technologies, bringing us closer to the goal of Artificial General Intelligence (AGI). As AI continues to evolve, models like DeepSeek will play a critical role in shaping the future of machine learning, making it possible for smaller teams to develop AI applications that can be deployed in diverse industries, from healthcare to finance and beyond.
In essence, DeepSeek represents a critical step forward in AI efficiency, democratizing access to high-performance AI systems and accelerating the pace of innovation in the field. As smaller teams leverage these breakthroughs, we may soon see the development of AI applications that were once the domain of only the largest corporations, further blurring the lines between research and real-world impact.